Atlassian · Guard Premium
Automating classification at enterprise scale
Mapping detections to classification labels so enterprise customers could meet data-classification requirements in Cloud - and shaping how the team validated scanning and configuration before customers saw it.
- Role
- Product designer
- Timeline
- 2025-2026
- Company
- Atlassian
The Challenge
Atlassian's enterprise customers required a robust security platform to protect their Atlassian Cloud data and meet compliance requirements. Delivering this capability directly supported Atlassian's objective of migrating its largest enterprise customers from Data Center ahead of its planned EOL.
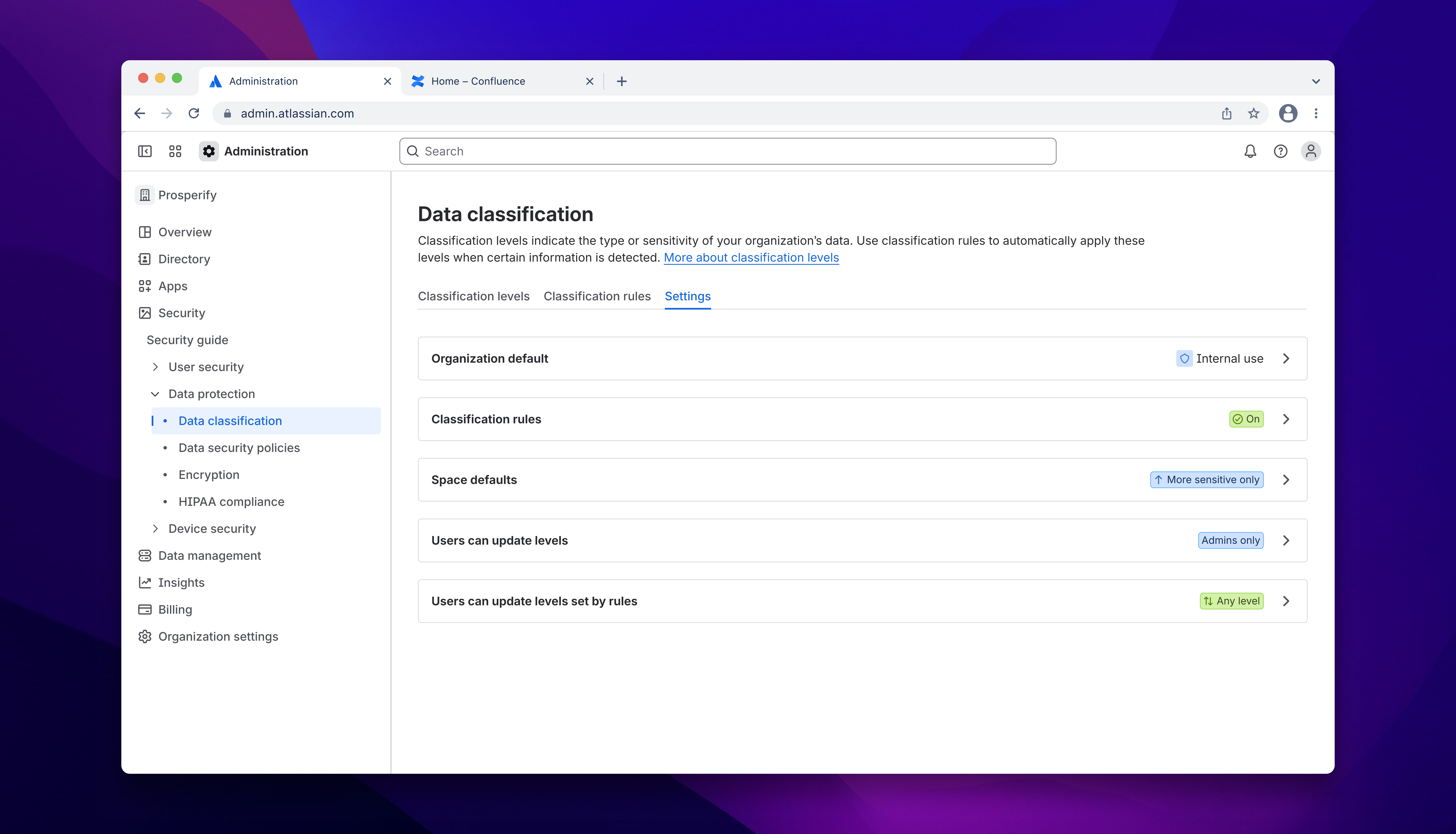
Atlassian Guard, our Cloud security offering, was a relatively new product that was not yet robust or mature - it had originated as a "start-up" product inside Atlassian that scaled rapidly but still had many gaps. One of the biggest gaps was automatic classification of content by sensitivity (labels applied when the system detects risk signals).
The opportunity
- Allow customers to automatically classify content by mapping content markers to classification labels, thus ensuring compliance in industries where data classification was a requirement.
- Make sensitivity labelling less dependent on manual vigilance - or even remove the need for manual classification altogether.
My role
As the product designer assigned to Autoclassification, I was responsible for the end-to-end* design vision and execution across the new feature. This included:
- Defining the problem space and driving alignment with cross-functional stakeholders
- Designing iteratively to scoped milestones
- Exploring rapidly and widely to drive decision making in the face of ambiguity and moving requirements
- Collaborating with stakeholders in the parallel workstreams of scanning and detections, to surface dependencies and touch-points.
- Aligning with stakeholders across multiple design systems to ensure UI consistency, creating custom patterns and components when required.
*When concept model for classification controls I put forward was accepted, I handed over my autoclassification work to another designer in order to focus entirely on the calculator and subsequent admin settings UI.
My approach
Milestone scoping
For the first milestone, I focused on delivering a drastically scoped down version that engineering could build rapidly in order to test the scanning engine internally. This involved identifying the core workflows that would not change, even given the ambiguity and multiple open questions the team was grappling with. Engineering were able to move quickly on my designs and the findings around latency, job visibility, intra-product signalling, and (the non-existent) conflict resolution logic laid the groundwork for future iterations.
Surfacing trade-offs
Engineering pressure pointed toward classifying in-flight content only. This path came with considerable trade-offs: inconsistent labels between historical and new content, unclear opt-in paths, and weak semantics for turning autoclassification off. Through stakeholder sessions, looms, and a variety of sense-making artifacts, I made the cost of that path visible. The plan was adjusted to encompass both contexts.
Exploring testing, versioning, previewing
With the first milestone in build, my focus shifted to how admins could preview and validate their autoclassification configuration without unacceptable risk. I produced multiple user journeys and partial hi-fi explorations in multiple directions, including scoped test runs, draft states, and sandboxes. Scope and roadmap pressure weighed heavily on these discussions: my goal was to surface creative options and their trade-offs within these constraints, not pick a pattern prematurely.
Handoff
In parallel to this work, the question of conflict resolution between classification methods had become an imperative. As the architect of that solution, I handed the preview thread to another designer to maintain momentum, and moved to Admin UI settings.
Outcomes
Autoclassification launched as an early access program in April 2026 under the new name "Data Classification Rules", enabling enterprise and highly regulated customers to automatically classify data at scale.